by Sergey Kovalev, Software Engineer at Altoros
Processing the same Apache Hive query may take a different amount of time, depending on how you optimize it. Knowing the right tricks can boost Hive performance by 2–3x or more.
In this post, I describe the most common strategies for optimizing Hive queries to improve performance. All the examples below are based on a simplified version of a real-life application data schema, where the application domain contains information about YouTube channels and videos.
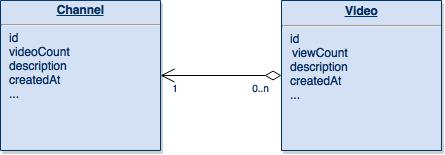
So, let’s see how you can make your Hive queries faster.
1. Use partitions whenever possible
Hive can be very helpfull if you need to perform full-table scans on a large amount of data. Very often, query results must be filtered by specific column values, such as region, state, or date, e.g., SELECT * from a video WHERE date=’2015-04-08’. By default, even if you use a where clause with particular values, Hive reads the full set of files in the table directory and applies the filter to it. This is inefficient and significantly increases query execution time. To overcome this issue, we can use Hive partitions.
create table video (
id STRING,
channelId STRING,
title STRING,
description STRING,
viewCount BIGINT
) PARTITIONED BY (uploadDate date)
STORED AS ORC;
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;
insert into table video PARTITION (uploadDate) select * from video_external;
Note that no partition columns are included into the table structure.
Partitions split data within a table and correspond to a particular value(s) of a partition column(s). Each partition is stored as a sub-directory within the table’s directory on HDFS.
If possible, only the required partitions of the table are queried during query execution.
In Hive, there is no way to efficiently delete or update records within a table. You can only drop or overwrite the whole table. Partitioning makes it possible to update and delete data in a more efficient way. We can drop or overwrite only a particular partition, if required.
It is important to take into account the cardinality of the partition column and avoid fragmenting data too much. Too many small files put preasure on HDFS NameNode, and the task of recursively scanning the directories becomes more expensive than a full-table scan.
2. Use bucketing
Bucketing is another approach to splitting data sets into more manageable parts, which may allow for more effective operations, such as joining two tables. If we bucket the video table and use ID column for bucketing, values of the column will be hashed into buckets by a user-defined number. Records with the same ID will always be stored in the same bucket. Assuming the number of video IDs is much greater than the number of buckets, each bucket will have many video IDs. While creating the video table, you can specify something like:
CLUSTERED BY (id) INTO N BUCKETS ;
Here, N stands for the number of buckets.
create table video (
id STRING,
channelId STRING,
title STRING,
description STRING,
viewCount BIGINT
) PARTITIONED BY (uploadDate date)
CLUSTERED BY(channelId)
SORTED BY(channelId)
INTO 32 BUCKETS
STORED AS ORC;
Then we need to populate the table:
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;
set hive.enforce.sorting=true;
set hive.enforce.bucketing=true;
insert into table video PARTITION (uploadDate) select * from video_external sort by channelId;
On the HDFS level, bucketing splits data within a table into a number of files that is equal to the number of buckets specified during table creation. If we use partitioning together with bucketing, then under each partition folder Hive creates a number of files that equals the number of buckets specified during table creation.
If two tables in a JOIN query are bucketed by JOIN keys, the M/R job splits can be arranged so that the map task will only work with particular buckets from these two tables. This makes it possible for Hadoop to avoid using reducers and perform all operations inside mappers, which improves performance. See the joins optimization section for a detailed explanation of how bucketing can help to improve performance of joins.
3. Use joins optimization
If we want to combine rows from two or more tables based on common fields, a JOIN clause is usually used. An appropriate JOIN strategy can dramatically improve performance of Hive.
Shuffle join/common join:
In Hive, the JOIN operation is compiled to a MapReduce task, which involves a map and reduce phase. A mapper reads from JOIN tables and emits the JOIN key/value pairs into an intermediate file. During the shuffle phase, Hadoop merges these pairs by key and sorts them by value.
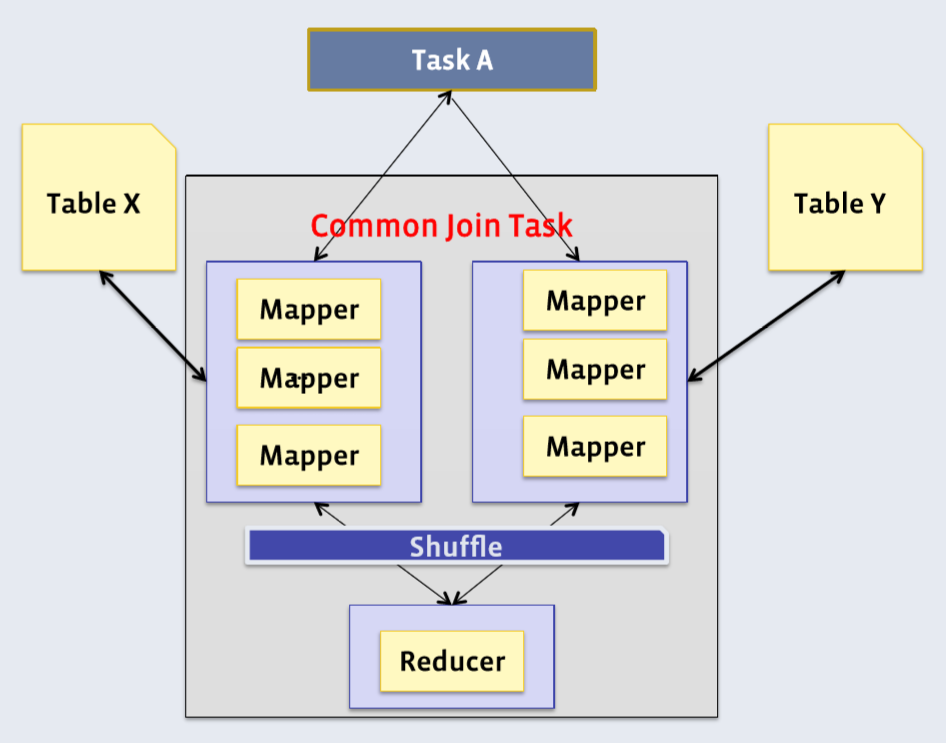
The shuffle phase is very expensive, because it requires transmitting lots of data over a network. There are several techniques that can help to overcome this issue.
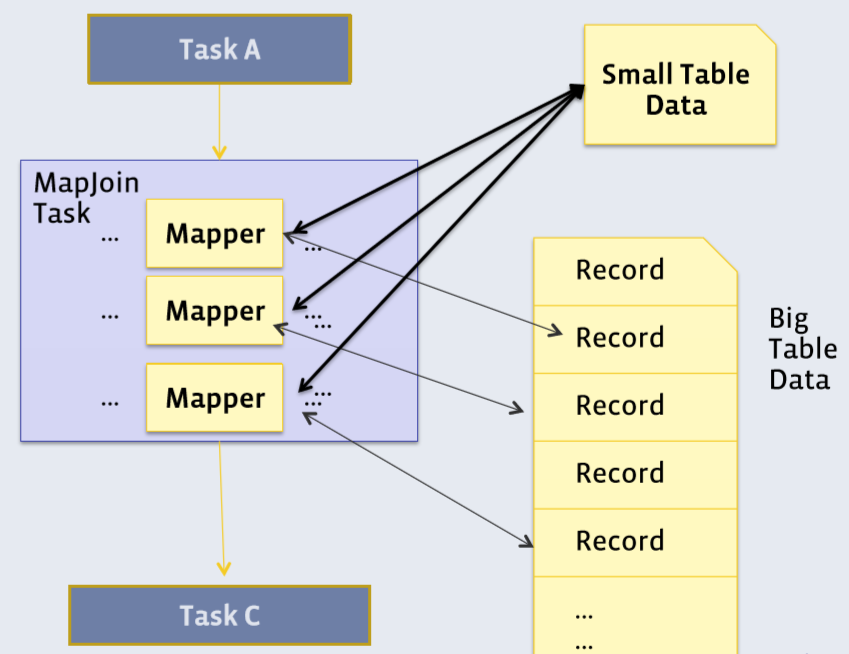
Map-side join:
In case one of the tables being joined is small enough to fit into memory, the join can be performed as a map-only job. Hive reads the small table as a hash table into Hadoop DistributedCache and streams records from the big table, joining each record with the hash table. As a result, the map-side JOIN query does not required a reducer. Unfortunately FULL/RIGHT OUTER JOIN still cannot be performed.
By default, auto-join is enabled and there is no longer a need to provide the map-join hints in the query.
The hive.auto.convert.join.noconditionaltask.size property
enables the user to control the size of a table that can fit into memory.
Bucket-map join/sort-merge-bucket (SMB) join:
If you split the data into buckets by JOIN keys for both tables, a bucket-map join can be used. The number of buckets in one table must be a multiple of buckets in the other table. To activate the bucket-map join, enter the command before running query:
set hive.optimize.bucketmapjoin=true;
In case both tables have the same number of buckets and the data is sorted by bucket keys, Hive query engine perform sort-merge join, which is even faster. To activate the sort-merge join, run the following commands before the query:
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;

See above for an example of how to create an SMB table.
If the tables don't satisfy the conditions, Hive will simply perform a regular shuffle join. In a general implementation, these JOIN strategies improve performance dramatically.
4. Choose the right input format
For analytical processing, it is very usefull to use the columnar storage format. In opposite to the usual approach of storing records row-by-row (video ID, video title, video comment count, etc.), the columnar storage format stores the records column-by-column (all names, all ages, all addresses, all salaries, etc.). This composition provides significant benefits for analytical processing:
- More effective type-specific compression can be applied for an entire column, since all the values have the same type.
- The query engine can skip loading columns whose values are not required to answer the query.
- Since all values for the column are stored consequently, it is possible to use vectorized operators on the column values.
Consider the ORC Files format or the Parquet format as your columnar storage format.
ORC files
Optimized RC Files were developed by HortonWorks to improve performance of Hive. ORC files have great compression options (some benchmarks claim that they provide the best compression in Hadoop). Apart from that, this format implements some similarity of indexes, which enables faster queries. There is a downside though—they ORC files don’t support schema evolution.
Parquet files
Parquet files are yet another columnar file format backed by Cloudera. As well as the ORC format, Parquet enjoys compression and query performance benefits. As an advantage, Parquet is supported by all Cloudera tools, including Impala. And, unlike ORC files, Parquet supports limited schema evolution. New columns can be added at the end of the structure.
5. Use vectorization
By default, Hive processes rows one by one. Each row of data goes through all operators before processing of the next one. This way is very ineffective in terms of CPU usage.
To improve efficency of CPU instructions and cache usage, Hive (version 0.13.0 and later) uses vectorization. This is a parallel processing technique, in which an operation is applied to a block of 1024 rows at a time rather than a single row. Each column in the block is represented by a vector of a primitive data type. The inner loop of execution effectively scans these vectors, avoiding method calls, deserialization, and unnecessary if-then-else instructions.
Vectorization only works with columnar formats, such as ORC and Parquet.
To enable vectorization, use this command:
set hive.vectorized.execution.enabled=true;
If possible, Hive will apply operations to vectors. Otherwise, it will execute the query with vectorization turned off.
6. Use cost-based optimization
Cost-based optimization (CBO) is a new feature in Hive 0.13, which may reduce query latency by examining the tables and conditions specified in the query and reducing resource utilization. CBO depends on up-to-date statistics on the volume and distribution of data. To gather statistics for the Hive query optimizer, set these two parameters:
set hive.compute.query.using.stats=true;
set hive.stats.dbclass=fs;
and then, within Hive, enter the command:
ANALYZE TABLE orc_table COMPUTE STATISTICS;
This will compute statistics for the table, which can then be utilized by Hive’s CBO engine.
7. Avoid highly normalized table structures
Normalization involves decomposing a table into smaller tables to decrease redundancy of data and anomalies. In other words, by normalizing your data sets, you create multiple relational tables that can be joined to get the results.
In Hive, joins require a reducer, which implies that the data has been sorted on the shuffle stage. Shuffling is a rather expensive and difficult operation, and it is one of the common reasons for performance issues. So, it’s a good idea to avoid highly normalized table structures, because they require JOIN queries to produce results.
8. Use parallel execution
Single, complex Hive queries usualy are translated into a sequence of map-reduce jobs that by default are executed sequentially. Some of the map-reduce stages in such queries are not interdependent and can be executed in parallel. The query can take advantage of spare capacity within the cluster and reduce the overall execution time.
To enable parralel execution, use:
SET hive.exce.parallel=true;
9. Set the hive.exec.mode.local.auto configuration variable
Hadoop can work in standalone, pseudo-distributed, and fully distributed modes. When the dataset to process is big, Hadoop runs in fully distributed mode. When the amount of data to process is small, starting distributed data processing will create unnecessary overhead. The following settings enable Hive to automatically convert a job to run in local mode:
set hive.exec.mode.local.auto=true;
10. Compress map/reduce output
The data compression option is used for decreasing the size of data, which is being transferred over the network between mappers and reducers. The compression mechanizm could be applied separately to the ouput produced by mappers and reducers:
- For map output compression, execute set mapred.compress.map.output = true.
- For job output compression, execute set mapred.output.compress = true.
11. Use the 'explain' keyword to improve the query execution plan
To get detailed information and see the query plan, add the EXPLAIN keyword before the query. The output is quite tricky and requires practice to understand.
As you have probably know, each query in Hive consists of one or several stages and each following stage can depend on the previous one. Every stage represents a MapReduce job, move stage, limit stage, or other tasks that Hive needs to accomplish for a complex query.

This is what plans of each stage look like:

If you want even more details, use the EXPLAIN EXTENDED keywords.
12. More on Hive
That’s it. Hope this post helps you to speed up your Hive queries. If you have questions or ideas on what you would like me to cover in upcoming posts, feel free to share them in the comments below.